
Apache Kafka Tutorial

Introduction
- Kafka is a distributed streaming platform (it lets you publish/subscribe messaging, fault-tolerant, message order)
- Kafka is a highly scalable, fault-tolerant enterprise messaging system.
- it’s used streaming applications as well
- Key abstraction of Kafka: Commit log (transaction log): persistent, replicated, you can have lots of it.
- it’s used as a real-time data pipelines (low latency < 10ms)
- it doesn’t publish messages itself, it waits for consumers
- When you publish data into a topic, these are spread over a set of machines and replicated for fault-tolerant.
- The topic is made up of a bunch of log shard/partition, and then each shard/partition is replicated
- if the controller will die, servers will reelect new controller
- it’s an open-source project since 2011.
- It can be used for streaming processing
- It can be used as an ETL tool with connectors
Definitions
- Message: Small to a medium-sized piece of data. For Kafka message is a simple array of byte
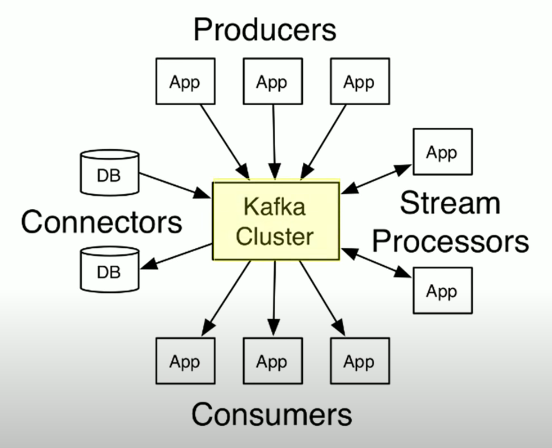
- Producer: An application that sends messages to Kafka cluster
- Broker: (Kafka Server) take messages from producers and store them into Kafka message log (commit log/Transaction log).
- Consumer: An application that reads data from Kafka, and does whatever they want to do. (send them to Hadoop, Casandra, HBase, push-back again into Kafka)
- Cluster: A group of computers sharing workload for a common purpose.
- Topic: A topic is a unique name for Kafka stream
- Partitions: Broker log can be huge, maybe larger than the storage capacity of a single computer. In that case, Kafka use partitions for spreading data. Kafka doesn’t care how many partitions required for a Topic. We have to take that decision. When we create a Topic we have to create partitions for every single machine.
- What is a stream: Continuous flow of data, constantly steam of messages, time-series data. Kafka gives you a stream and you can use the stream in other stream processing frameworks.
- Connectors: They are ready to use connectors, import data from DBs into Kafka, or export data from Kafka to DBs
- Offset: a sequence id given to messages as they arrive in a partition. offset never change, there is no global offset across partitions. every partition has own offset order.
- We have two type of offset
- Current offset: when we pool messages from kafka. we get more then one messages. current offset is last given message to the consumer.
- Committed offset: last processed message from last given message group.
- We have two type of offset
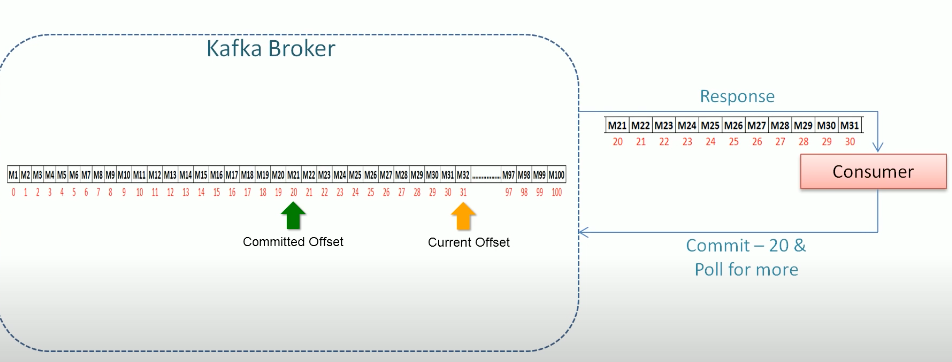 in this picture kafka gives 30 messages for every pool request.
when the consumer processed one messages of 30 records, consumer send message to do kafka
according this picture, Current offset is 31, committed offset is 20.
in this picture kafka gives 30 messages for every pool request.
when the consumer processed one messages of 30 records, consumer send message to do kafka
according this picture, Current offset is 31, committed offset is 20.
-
committed offset is very important for rebalancing activity.
-
Locating messages: if you want to locate massage you need
-
- Topic Name
- Partition Number
- Offset number
-
Consumer group: A group of consumers acting a single logical unit.
-
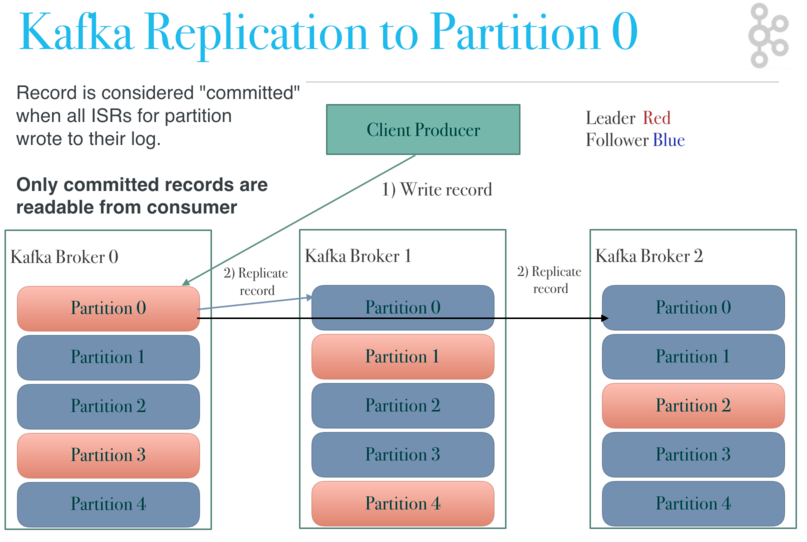
Replication factor: number of total copies of partitions, one of them active (leader) the others passive (followers). we define the replication factor for each topic and applied all partition in the topic. The broker can be follerwer for some partitions at the same time can be a leader for some partitions.
-
ZooKeeper: is part of the Hadoop project, centralized service for maintaining configuration information, naming, providing distributed synchronization. Kafka uses zookeeper coordinating among brokers.
-
Zookeeper is the storage of the state of a Kafka cluster. It is used for the controller election either in the very beginning or when the current controller crashes. The controller is also responsible for telling other replicas to become partition leaders when the partition leader broker of a topic fails/crashes.
-
Is the controller the leader?: Not really.. Each partition has its own leader.
-
ISRs: in-sync replica list,
-
Kafka Controler: is a Kafka service that runs on every broker in a Kafka cluster, but only one can be active (elected) at any point in time. which is responsible for state management of partitions and replicas
-
Kafka Controler election: simply a random replica in the in-sync replica list aka ISRs of that partition
-
How many Kafka Controler?: Within a Kafka cluster, a single broker serves as the active controller which is responsible for state management of partitions and replicas. In order to find which broker is the controller of a cluster you first need to connect to Zookeeper through ZK CLI:
-
./bin/zkCli.sh -server localhost:2181
-
zk: localhost:2181(CONNECTED) 0] get /controller
-
Kafka can also resolve bottleneck problems, Kafka can scale itself horizontally using partition/brokers
-
Where can we use Kafka?
-
- Kafa resolves data integration problems, we need to create producer and consumers, Kafka connectors
- We can use Kafka for serious of validations, data transformations, and build complex data pipelines.
- We can use Kafka to collect information for later consumption.
- We can use it log transactions and create applications to responding realtime.
- Exchanging data between microservices.
- Server: The server is a single computer and we can install a sample Kafka Broker on each server. In Kafka Cluster, every server works actively, there is no idle server. Each Kafka server has some episodes of the Subject and works as a copy for some episodes, but also acts as a leader for some episodes. This means there is no idle server. If you want to scale the load for some Topics, you can create partitions as many as your server number. Your Kafka client library contains Partitioner, and partitioner chooses a partition (round-robin) for the message.
Quick Start
- Download https://kafka.apache.org/downloads Kafka and extract files, installation not required.
- run following commands in terminal windows
cd bin
# run follewing commands with different terminal window
# Start the ZooKeeper service
$ ./zookeeper-server-start.sh ../config/zookeeper.properties
# Start the Kafka broker service
$ ./kafka-server-start.sh ../config/server.properties
# create Topic
$ ./kafka-topics.sh --create --topic quickstart-events --bootstrap-server localhost:9092
# display usage information
$ ./kafka-topics.sh --describe --topic quickstart-events --bootstrap-server localhost:9092
# write some events into the Topic
$ ./kafka-console-producer.sh --topic quickstart-events --bootstrap-server localhost:9092
# read the events
$ ./kafka-console-consumer.sh --topic quickstart-events --from-beginning --bootstrap-server localhost:9092
# list topics
$ ./kafka-topics.sh --list --zookeeper localhost:2181
Kafka Cluster: implements “Leader & Follower” model. The leader takes care of all client interactions. Other partitions just copy all data from the leader. In an ideal cluster we install one broker to one computer.
Configuration
- broker.id: The id of the broker. This must be set to a unique integer for each broker.
- listeners: (default 9092) it’s a port number that is used communicating producers and consumers.
- log.dir: The main data directory of a broker.
- zookeeper.connect: zookeeper connection string, every broker have to know zookeeper address, it’s used to form a cluster. All brokers running on different system and they know each other with zookeeper
- delete.topic.enable: (default: false) By default deleting Topic not allowed, it’s a reasonable in production environment
- auto.create.topics.enable: if producer start sending message with non existing Topic kafka create Topic automatically
- default.replication.factor: (default:1) one partition with single copy.
- num.partitions: (default:1) one partition
- log.retention.hours:(default:168 hours/7 days) data in kafka is not retains forever, kafka is not a database. it’s a message broker.
- log.segment.bytes: is data-size reaches this value, kafka start to cleanup activity. it’s not a Topic size, it’s a partition size.
- max.in.flight.requests.per.connection: how many messages can send to server without receiving response.
- acks: is to configure acknowledgment
- acks=0 : producer will not wait for the response
- acks=1 : producer will wait for the response, however response will sent by the leader. if the leader will not sent the response, producer retry after few miliseconds.
- acks=all : slowest but reliable methods. because leader will wait all replicas acknowledment.
Kafka Client Library - Java
- Class KafkaProducer: it’s a java object used for creating kafka producer.
- Class ProducerRecord: we use this class for creating any kafka messages.
- Jar kafka.clients: it’s a maven repository for implementing producers and consumers.
Producer
import java.util.*;
import org.apache.kafka.clients.producer.*;
public class MyProducer {
public static void main(String[] args) throws Exception{
String topicName = "TopicA";
Properties props = new Properties();
// Kafka brokers, every broker has some partitions from some topics.
props.put("bootstrap.servers", "localhost:9092,localhost:9093");
props.put("key.serializer","org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "io.confluent.kafka.serializers.KafkaAvroSerializer");
props.put("schema.registry.url", "http://localhost:8081");
// 1- Create Producer
Producer<String, MyRecord> producer = new KafkaProducer <>(props);
// 2- Create ProducerRecord
MyRecord mr = new MyRecord();
mr.setId("10001");
mr.setChannel("HomePage");
mr.setIp("192.168.0.1");
ProducerRecord<String, MyRecord> producerRec = new ProducerRecord<String, MyRecord>(topicName, mr.getId().toString(), mr);
// 3- send data
try{
// producer.send(producerRec); // Fire & Forget
RecordMetadata acknowledge = producer.send(producerRec).get(); // Synchronized
// producer.send(producerRec, new MyCallBack()); // Asynchronized
System.out.println("Complete");
}
catch(Exception ex){
ex.printStackTrace(System.out);
}
finally{
producer.close();
}
}
}
class MyCallBack implements Callback{
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception c){
if(e!=null){
System.out.println(e.printStackTrace());
}
}
}
- ProducerRecord(String topic, Integer partition, Long timestamp, K key, V value): we can put timestamp into our message.
- You want to send message into same partition you can give same Key number for each message.
- “Integer partition” : this ProducerRecord parameter indicates, you want to disable default partitioner, and you are hardcoding a partition in your message itself. Kafka will not determine suitable partition for your message. If you want to send message “partition 0” you can give parameter 0.
Consumer
import java.util.*;
import org.apache.kafka.clients.consumer.*;
public class MyConsumer{
public static void main(String[] args) throws Exception{
String topicName = "TopicA";
String groupName = "RG";
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092,localhost:9093");
props.put("group.id", groupName);
props.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer", "io.confluent.kafka.serializers.KafkaAvroDeserializer");
props.put("schema.registry.url", "http://localhost:8081");
props.put("specific.avro.reader", "true");
KafkaConsumer<String, MyRecord> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList(topicName));
try{
while (true){
ConsumerRecords<String, MyRecord> records = consumer.poll(100); // 100ms timeout
for (ConsumerRecord<String, MyRecord> record : records){
System.out.println("Session id="+ record.value().getId()
+ " Channel=" + record.value().getChannel()
+ " Referrer=" + record.value().getReferrer());
}
}
}catch(Exception ex){
ex.printStackTrace();
}
finally{
consumer.close();
}
}
}
-
bootstrap.servers: broker list
org.apache.kafka.common.serialization.StringSerializer: We have to convert data to a byte array before sending Kafka. StringSerializer provides String to a byte array. we can develop custom serializer.
org.apache.kafka.common.serialization.IntegerSerializer: it provides Integer to byte array.
producer.close(): you have to call after every message.
Custom Serializer: if you want to send a custom object to Kafka, you can to implement custom serializer and deserializer. But you can also use generic serializer (Avro, protobuf)
Custom Message Object: we have to implements org.apache.kafka.common.serialization.Serializer
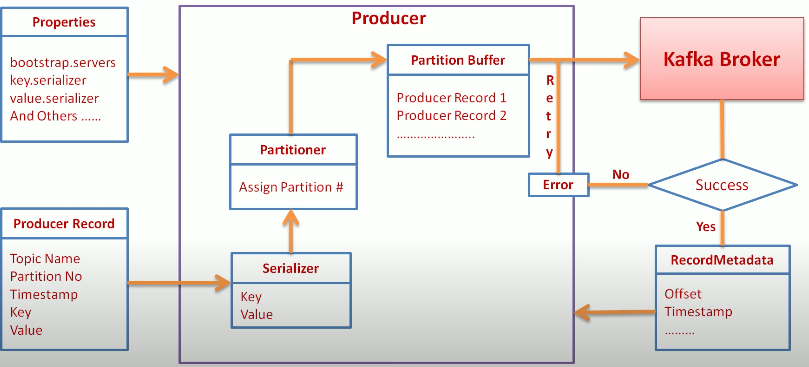
interface. and we need to override interface methods. partitioner: it’s choosing a partition for the current message. we can give “Key” value for the same partition. “Key” ‘s value Indicate partition. if “key” is not specified, it’ll use round-robin, we can implement custom partitioner. if you want to make custom partitioner you have to implement partitioner interface.
the producer is in the Client library, and it has a buffer. it sends message firstly “partition buffer” then batch process send buffer messages to Kafka.
Default Partitioner:
- if a partition is specified in the record, use it
- if no partition is specified but a key is present choose a partition based on a hash of the Key
- if no partition or key is present choose a partition in a round-robin fashion
Sending Methods
- Fire and Forget: send and don’t expect a response.
- Synchronous Send: wait until get a response. response will be success or exception. “.get()” means wait until response. producer.send(record).get();
- Asynchronous Send: it provides callback function for later responses. You can record exception for later analysis
- We can specify “Retry” count with the configuration, default retry value is 100 ms
Kafka Connect APIs
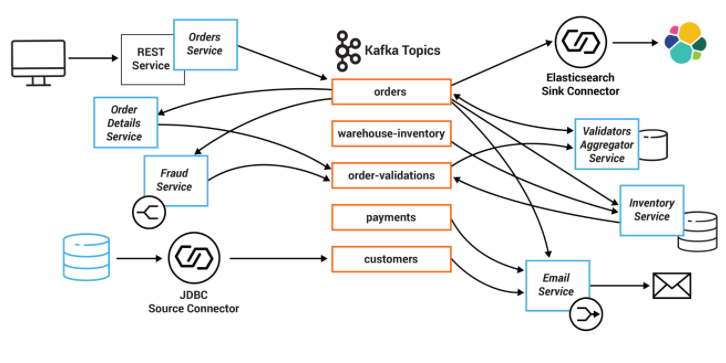
-
Kafka provides communication between microservices, it is not used on RESTful communications for example between a client application and authorisation service. It working like a backbone network router
-
We will use Object to byte serializers to communicate between microservices.
-
Avro: (KafkaAvroSerializer) Typical serialization system offers the following
-
- Allows you to define a scheme for your data.
- Generates code for your schema (Optional in Avro)
- Provide APIs to serialize your data according to the schema and embed schema information in the data.
- Provide APIs to extract schema information and deserialize your data based on the schema.
-
we can define our schema as a JSON format
Example Schema:
{ "type": "record", "name": "ClickRecord", "fields": [ {"name": "session_id", "type": "string"}, {"name": "browser", "type": ["string", "null"]}, {"name": "campaign", "type": ["string", "null"]}, {"name": "channel", "type": "string"}, {"name": "referrer", "type": ["string", "null"], "default": "None"}, {"name": "ip", "type": ["string", "null"]} ] }```
Define schema:
```java // Producer: props.put(“schema.registry.url”, “http://localhost:8081”);
// Consumer props.put(“schema.registry.url”, “http://localhost:8081”); props.put(“specific.avro.reader”, “true”); ```
-
We will generate our DTO objects with Kafka Avro, and we will use its communication
-
Schema Registry: a confluent service, we can download it run it our system.
-
Kafka connectors are ready to use plugins,
-
That’s what the Kafka connectors is designed for.
-
Source Connect: it’s a Kafka producer.
-
Sink Connector: it’s a Kafka consumer.
-
Kafka Connect Framework: provide implementing new Kafka connector, (Source connector, Sink connector, SourceTask, SinkTask)
-
Kafka Transformations: Kafka connect provide, Single Message Transformations (SMTs)
-
We can also put custom properties into the properties object.
-
Kafka Connector can scale itself like consumer groups, all we need to do start all workers with the same group id.
-
Kafka Connector groups (Connect Cluster) are
-
- Fault-Tolerant
- Self Managed
-
Kafka connectors will give you
- Reliability
- High Availability
- Scalability
- Load Balancing
- We can configure the connectors using the command-line tool, it also provides REST API methods.
Kafka Streams APIs
You can classify Kafka APIs into two parts, producer APIs and consumer APIs
Kafka Connect API, Single Message Transformation API
Producer Group?
- It’s as simple as executing another instance of producer, there is no coordination or sharing of information is needed among producers
Consumer Group
How do we read messages in parallel: We can do that creating consumer group, Kafka allows reading data once. Group Coordinator: manage the list of group members, if new consumer added, Coordinator reassign couple of consumer-partitions. rebalancing. rebalancing activity. Consumer group: it is not about multiple application reading data same topic, it about single application multiple consumer reading about single topic.
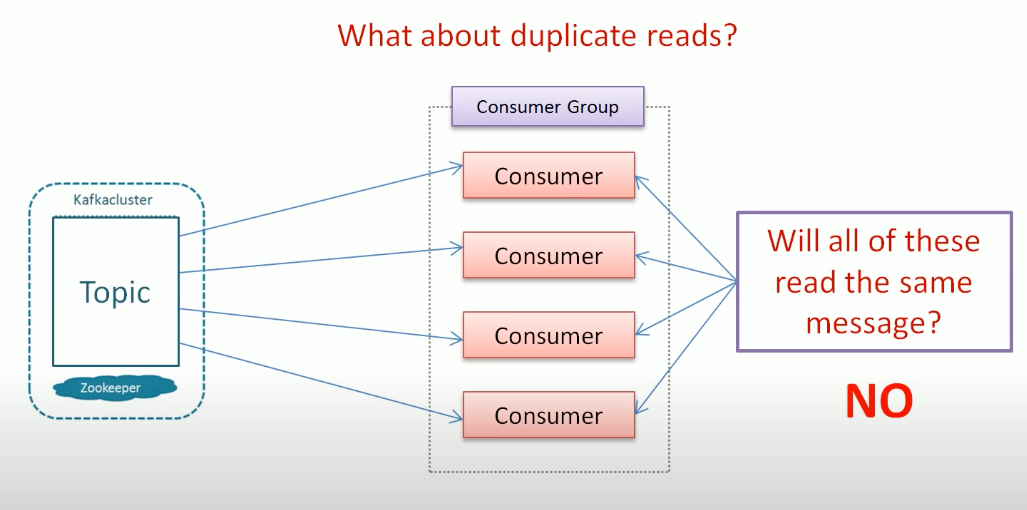 only one consumer have partition at the same time.
only one consumer have partition at the same time.
- There is no way we can read a massage more then once
- If you want to read messages more then once, you can create another consumer group. But in this case every consumer groups read same data. Each group will have a different offset.
- If all the consumer instances have different consumer groups, then each record will be broadcast to all the consumers.
- According concept we can create consumer per partition. if we have 4 partition, best practice is create 4 consumer. Create a group: by adding KafkaConsumer properties “group.id” parameter. all other things (Group coordinator etc.) provided by API.
Collecting Data from Devices
-
Which one should I choose? : Topic per sensor? Topic for device? Topic for sensorType? Topic for DeviceType?
It depends on your semantics:
- a topic is a logical abstraction and should contain “unify” data, ie, data with the same semantical meaning
- a topic can easily be scaled out via its number of partitions
For example, if you have a different type of sensors collecting different data, you should use a topic for each type.
Topic per device or sensor is not sustainable: Since devices can be added or removed also sensors can be added or removed. You will try to find out a way to create these topics and partition on the fly.
The common wisdom seems to be: put all events of the same type in the same topic, and use different topics for different event types.
If device metadata (to distinguish where the date comes from) is embedded in each message, you should use a single topic with many partitions to scale out., best practice is to over partition your topic from the beginning on to avoid adding new partitions.
Confluent Schema Registry : It encourages you to use the same Avro schema for all messages in a topic.
Relational databases: order is important if you have a transaction you have to put all transaction steps into the same topic. We have to define Topic base on transactions
- The most important rule is that any events that need to stay in a fixed order must go in the same topic (and they must also use the same partitioning key). So, as a rule of thumb, we could say that all events about the same entity need to go in the same topic.
USE CASES
- Between microservices
- Alarm Service: consumes “Alarm” topic (other services can put data into “Alarm” topic in case of any emergency situations)
- Email Service: consumes “E-mail” topic for sending emails
- Notification Service: consumes “Notification” topic,
- Configuration Service: consumes “Configuration” topic, produce to another topic
- Performance service
- CLI service
- Timer Service
- Resource Service
- License Service
- Profile Service
- Authentication Service
- Authorization Service
- Log Service
- Correlation Service
- BigData Service
- Monitoring Service
- Analytics Service
- Collect data from devices (IoT) with Kafka Connectors
- Metrics
- Website Activity Tracking (feeds some dashboard widgets)
- Log Aggregation
- Streaming Processing
- Event Sourcing
Data Size of Messages
for sending rows from database, how many rows should I send per message.
Best practices:
- Each topic in Kafka has at least one partition, if you have n topics, you inevitably have at least n partitions
- Topic=Collection of events of the same type
references:
https://www.logicbig.com/tutorials/misc/kafka/automatic-partition-assignment-to-consumers.html
https://www.confluent.io/blog/put-several-event-types-kafka-topic/
https://stackoverflow.com/questions/39735910/kafka-topic-per-producer?answertab=active#tab-top
https://docs.confluent.io/platform/current/tutorials/examples/microservices-orders/docs/index.html
https://www.youtube.com/watch?v=k8XhuE1PE7A&list=PLkz1SCf5iB4enAR00Z46JwY9GGkaS2NON&index=9
Date: 2021-01-23